Hanselminutes Podcast 102 - Mike Pizzo on the ADO.NET Entity Framework
 My one-hundred-and-second podcast is up. In this episode, I sit down with Michael Pizzo, the Principal Architect of the ADO.NET Entity Framework. He gets technically down and dirty pretty fast and I get answers to all the hard questions like "Are LINQ to SQL and LINQ to Entities competing?" and "Which one should I use?" A very cool guy and a fun interview that finally set my head straight about the data stack.
My one-hundred-and-second podcast is up. In this episode, I sit down with Michael Pizzo, the Principal Architect of the ADO.NET Entity Framework. He gets technically down and dirty pretty fast and I get answers to all the hard questions like "Are LINQ to SQL and LINQ to Entities competing?" and "Which one should I use?" A very cool guy and a fun interview that finally set my head straight about the data stack.
Subscribe: 

- Download: MP3 Full Show
- ACTION: Please vote for us on Podcast Alley! Digg us at Digg Podcasts!
If you have trouble downloading, or your download is slow, do try the torrent with µtorrent or another BitTorrent Downloader.
Do also remember the complete archives are always up and they have PDF Transcripts, a little known feature that show up a few weeks after each show.
Telerik is our sponsor for this show.
 Check out their UI Suite of controls for ASP.NET. It's very hardcore stuff. One of the things I appreciate about Telerik is their commitment to completeness. For example, they have a page about their Right-to-Left support while some vendors have zero support, or don't bother testing. They also are committed to XHTML compliance and publish their roadmap. It's nice when your controls vendor is very transparent.
Check out their UI Suite of controls for ASP.NET. It's very hardcore stuff. One of the things I appreciate about Telerik is their commitment to completeness. For example, they have a page about their Right-to-Left support while some vendors have zero support, or don't bother testing. They also are committed to XHTML compliance and publish their roadmap. It's nice when your controls vendor is very transparent.
As I've said before this show comes to you with the audio expertise and stewardship of Carl Franklin. The name comes from Travis Illig, but the goal of the show is simple. Avoid wasting the listener's time. (and make the commute less boring)
Enjoy. Who knows what'll happen in the next show?
About Scott
Scott Hanselman is a former professor, former Chief Architect in finance, now speaker, consultant, father, diabetic, and Microsoft employee. He is a failed stand-up comic, a cornrower, and a book author.
About Newsletter





My concern about the proliferation of these technologies is the shear amount of layers between you and what you want.
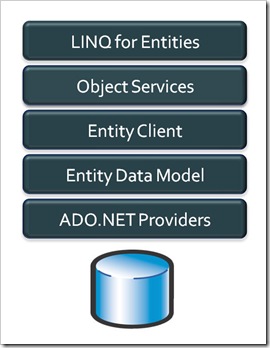
My application -> Linq -> Linq 2 Entities -> Entities Framework -> ADO.NET -> ADO.NET/Entities Provider -> Database.
I'd be very interested in seeing benchmarks.

I dunno....while it's true that the more we abstract the more cost increases on the activity. But this has been true forever, unless you are writing in Assembly, right on top of the CPU you are abstracting.
But in my mind, in the chain of events the most costly step I would guess is the last...the actual query, all the other steps (pardon me if I am over simplifying) is just code talking to code. So while there are more steps, in comparison to the query cost I think it's largely negligible. And that the benefits outweigh the costs. Which is a fundamental argument for ORM's anyway (which let's face it, Entity Framework is). But having said that there are limits too. :-)
It all comes down though to the right tool for the job...if your app is heavily reliant on extreme response times and performance then abstraction in any amount is probably not acceptable. But if you are writing an app where a hundred milliseconds here and there isn't an issue (which is probably a fair amount of business apps) then it's no biggie in the long run.


I've recently deployed a smallish EDF web app to a fairly high-traffic site and have been very impressed thus far. Since the small project has gone so well, I'm highly considering it for a larger project with a couple dozen entities. Ease of development and being able to query my data in an ad-hoc manner has been a great time saver.
Currently the designer tools are very good, but don't yet expose all of the features you'll commonly need when designing an entity model. For example, if you have a field that gets automatically populated from the DB that isn't the primary key, you have to edit the XML to set an attribute to pull it back. I'm hoping for a new beta soon that might expose this common scenario in the designer, but there's been no official word other than "it's coming."

Tom

>>Richard Bushnell writes: How about an interview with a guy from the LINQ-to-SQL team? <snip> Would they say something else, different to what Mike says?
Note that The Data Programmability Team owns both LINQ to SQL and LINQ to Entities so yes, hopefully we’d say the same thing... :-) That said, I was disappointed that we didn’t have more time to talk about some of the cool stuff in LINQ to SQL, and Scott and I have discussed having someone from the team working on the next version of LINQ to SQL talk about that technology in more detail.
>>Blah blah blah Performance blah blah blah… :-)
Several people wrote about performance. As I mentioned, there is overhead for first-time execution in loading metadata, generating a provider query from either an EntitySQL or LINQ expression, and generating the Lightweight CodeGen to construct objects and get/set persistent properties. The good news is that, for repeated execution, especially if you use CompiledQueries, that cost is only paid once; we cache the actual generated store query and execute it directly on subsequent requests. There is still some overhead with materializing results as domain objects, but with lightweight codegen this is as efficient as if you wrote the code to explicitly construct and set properties yourself.
Regarding Adnan’s question on large tables; note that the query actually is always evaluated in the database (which, as you say, is what the database was designed for). On the client we simply take the user query, written in terms of the conceptual model, and expand it to be in terms of the actual storage model, then send the expanded query to the back-end to evaluate. As above, this expansion process is done once for any EntitySQL query or compiled LINQ query and repeated execution simply executes the same query over and over again against the store (which most databases are *really* good at optimizing). In any case, we *never* do filtering, joining, etc. on the client.
I am working on pulling together some benchmarks that we can share on performance, so please stay tuned. The short answer to Tom, however, is that we don’t believe it would be worth it for other relational providers (such as Oracle) to implement their own IQueryable.
Thanks again for listening and taking the time to send great comments!
-Mike

However, it took me less than a day to learn how to make use of the entity stuff and write all the code that saves the read data to the DB. It took another 1.5-2 days to rewrite it using the stored procs and I'm a very fast typist. Additionally, data imports tend to have a lot more data in a lot more tables than your average data access method.
Rule of thumb: for heavy data access like that used in a large data import - go back to basics. For everything else use LINQ and the generated entities because it's fast enough and seriously reduces development time.

Comments are closed.
How about an interview with a guy from the LINQ-to-SQL team? I've heard quite a bit about the Entity Framework, but how do the guys working on the LINQ-to-SQL project see the relationship between the two products? Would they say something else, different to what Mike says?
Best regards,
Richard