The Case of the Failing Disk Drive or Windows Home Server Saved My Marriage
 I bought an HP MediaSmart Windows Home Server last Christmas, and haven't thought much about it since. It sits on the shelf and is pretty.
I bought an HP MediaSmart Windows Home Server last Christmas, and haven't thought much about it since. It sits on the shelf and is pretty.
Actually, that's not totally true, I did upgrade it to Power Pack 1 recently, but that was a 10 minute thing. For the most part, it's a conversation piece on a shelf in my new(ish) home office.
Now, the story. I sold my wife's laptop to Shawn recently as she wasn't laptop-ing much and wanted the speed of a desktop. I gave her my old Developer Rig with 32-bit Vista SP1 and she's cool with her browsing and her wifely blog and what-not.
A few weeks later she comes to me and we have a conversation that went (something like):
"This computer sucks. It's freaking out and now it says something about being smart. Let me tell you, mister, it's not smart."
What do you mean smart? Oh, wait, do you mean S.M.A.R.T.?
Smart, dumb, whatever, it's not booting. Let's get a Dell! Are my files backed-up?
 Ok, wait a second. I go upstairs and I see this. I'm like, that's weird. The floppy drive is pushed in. That's odd. Whatever. I blow it off.
Ok, wait a second. I go upstairs and I see this. I'm like, that's weird. The floppy drive is pushed in. That's odd. Whatever. I blow it off.
I go into my stash and pull out a hard drive. It's a 160gig that will replace the 80gig in her machine.
I open it up (it's a tool-less case) and swap out the drive. I can't find my Windows Home Server Restore CD so on my other machine I go to \\server\software\Home PC Restore CD and there's a readme.txt file that says:
"If there is a CD image file (RestoreCD.iso) in this folder, it is outdated.
To create a Home Computer Restore CD, download the ISO image file (RestoreCD.iso) from the Microsoft Web site at http://go.microsoft.com/fwlink/?LinkID=104683."
Cool, looks like the Power Pack 1 needs a new Restore CD. I download it and use the best image burning software out there, ImgBurn and I'm on my way.
I boot off the CD and get a nice Windows-looking interface and a wizard. It finds my Home Server, prompts me for a password and somehow automatically (probably via IP or Mac Address or some magic computer hash?) figures out which computer I'm trying to Restore. It automatically selects WifelyPC out of the list of a half-dozen machines in the house. I hit Finish and it takes like 11 minutes (creepy fast) to restore.
Boom. It's back. Total time elapsed, with drive swap, ISO download and burn was like 35 minutes. If I'd downloaded the ISO back when I got PP1 like I should have, it would have been a 15 minute operation. It was like using Norton Ghost in the old days, except without the DOS driver disk, the network goo, and general hassle. Couldn't have been easier except if there were no buttons to push at all.
Problem solved, and I'm the hero. The next two days involve me fitting this into casual conversation:
"Did I mention I brought your computer back from the abyss? Seriously. It's like Tivo. I just put it back the way it was at 2am on Tues. Isn't that cool? Love me!"
Something like that. I think the Love Me part was implied.
Fast forward to today.
"I'm sick of this freaking computer. It's clanking."
Uh oh. Clanking is rarely good. Actually, never good.
"I want a Dell. Uncle Ronnie got a Dell, where's my Dell?"
I return to my wife's office and see this after opening the side of the case:

Not clear? Let me add some John Madden commentary:

 Same thing as before, except this time my brain is working. It seems that the 2 yr old, pictured here, the face of pure evil, pushed on the front of the floppy drive. (Yes, I have a floppy. No, I don't know why. It's vestigial, OK?)
Same thing as before, except this time my brain is working. It seems that the 2 yr old, pictured here, the face of pure evil, pushed on the front of the floppy drive. (Yes, I have a floppy. No, I don't know why. It's vestigial, OK?)
The floppy drive is set in a larger "shell casing" that should have been screwed and secured into the larger case. Was it? Of course not. I'm a putz.
Of course I totally blamed the child. He can take it.*
Shoot, so that's two dead hard drives. But! The Home Server had taken it's nightly snapshot, again, after I'd restored it the first time. This included any changes The Wife had made the the machine in the last two days.
In fact, since I've upgraded my original 1TB Home Server with two extra drives, I've got backups going back into July.
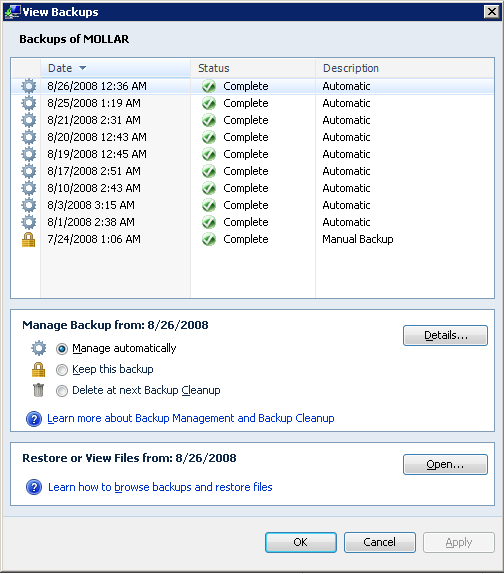
The backup management is set by default to keep 3 months of monthly backups, 3 weeks of weekly and 3 days of daily. That's pretty good coverage.
If you look at the very first picture, you'll see an external Western Digital MyBook that backs up the Home Server itself. I'm also a Mozy user, but it doesn't support Home Server, so I'm considering using KeepVault's specialized Home Server Product for Cloud Backup.
It's good to have a Backup Strategy. What's yours?
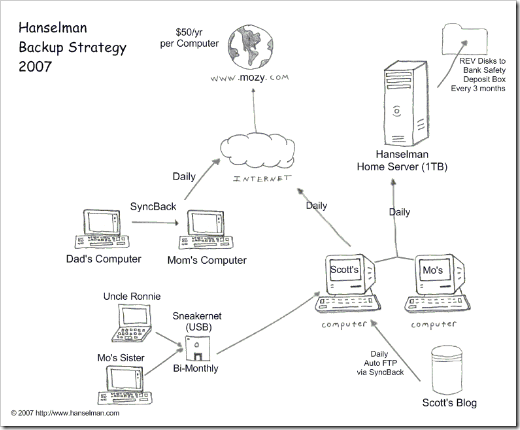
I'm happy with the Home Server and definitely recommend it.
Related Posts
- Rory Blyth, Chris Sells and Me in on10's Show Us Your Home: Scott Hanselman Edition
- Also known as "Geek Developer Cribs"
- Hanselminutes Podcast 71 - Windows Home Server - Interview with Charlie Kindel
- Review - HP MediaSmart Windows Home Server
* Don't worry, my wife saw right through it and now I'm in trouble for trying to pin this rap on the cherub. Look at that face!
About Scott
Scott Hanselman is a former professor, former Chief Architect in finance, now speaker, consultant, father, diabetic, and Microsoft employee. He is a failed stand-up comic, a cornrower, and a book author.
About Newsletter


 The general idea os:
The general idea os:
 BlogSvc.NET - The AtomPub Server for WCF and .NET
BlogSvc.NET - The AtomPub Server for WCF and .NET