Is Open Source a Crap Idea?
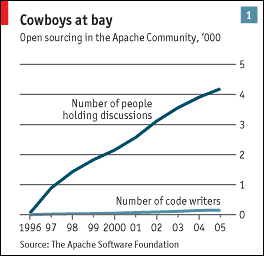 The graph at right is from a story in the Economist on Open Source. It illustrates, fairly effectively, that talking and doing are very different and that it's way easier to talk than do - or at least, it must be since so few people do and so many talk.
The graph at right is from a story in the Economist on Open Source. It illustrates, fairly effectively, that talking and doing are very different and that it's way easier to talk than do - or at least, it must be since so few people do and so many talk.
There are a number of choice tidbits in the article. This sure is true:
"The contributors are typically motivated less by altruism than by self-interest."
When I joined the DasBlog project after the 1.6 release, it was totally because DasBlog wasn't meeting my needs (scale, features, etc) and I thought it'd be easier to contribute than to jump to another engine. Omar has said before that he joined the team to be a better programmer.
As I worked on it more, I used DasBlog, selfishly, as a place to try out ideas and techniques that I would eventually put to use at work.
"Of the roughly 130,000 open-source projects on SourceForge.net, an online hub for open-source software projects, only a few hundred are active, and fewer still will ever lead to a useful product."
Yikes. That's scathing; I wonder if it's true. SF seems a lot more active and vibrant than that to me, but I could be just seeing what I want to see. Only a few hundred active projects?
With all projects there's a lot of talk, and a lot of time pressure as everyone has a life. It's a little frustrating when folks submit a bug when they could submit a bug and a patch. CVS and Universal Diffs make this a lot easier, but I'm as guilty as the next guy. If it's not fantastically simple to post a patch and have it heard, who has the time to bother? Stuart has offered a number of patches to Subversion, and really struggled to get them into the final product - or even to be heard.
How easy should it be? Is "Right-Click | Make Patch" then "email patch" easy enough?
I'm sure there are (sadly) lots of folks who submitted bugs or asked for help but just happened to pick a bad week where Omar, myself, Tom or the rest of the team was busy with life.
Aside: I wonder if there are crucial patches to the Linux Kernel that didn't get in because Linus had a bad day when the patch was submitted?
It's very difficult to get folks to commit themselves to a project that pays them nothing. The hours are long, the tech support brutal, the users unforgiving and the bugs neverending.
If you work on a Open Source Project, why do you do it? When will you stop?
About Scott
Scott Hanselman is a former professor, former Chief Architect in finance, now speaker, consultant, father, diabetic, and Microsoft employee. He is a failed stand-up comic, a cornrower, and a book author.
About Newsletter




 UPDATE: For those who couldn't find it, here's
UPDATE: For those who couldn't find it, here's 