Tips for Preparing for a Technical Presentation
I felt pretty good about my presentation at PDC last week. They are WAY more uptight about presentations at PDC than at TechEd. You have to go through dry-runs and slide reviews and all sorts of things that I was dodging at every turn.
The talk is available, as are all PDC talks, up at http://sessions.microsoftpdc.com. You can get them in these formats WMV-HQ, WMV, Zune, MP4 which is cool. I like the WMV-HQ version, over the WMV version, because it includes picture-in-picture video. My talk is no fun if you can't see me being silly. You can also watch it streaming in the browser via Silverlight and download my PPTX. If you saw it live, don't forget to evaluate the session as I have to Crush Anders in the scores. (Note to self, register CrushAnders.com and .net)
Anyway, someone was asking how I prepare for a talk, so I figured this would be as good enough time as any for a post on the topic.
 These basic tips from a few years back still stand - 11 Top Tips for a Successful Technical Presentation, but this post is about the actual preparation process and some tips and techniques that might help.
These basic tips from a few years back still stand - 11 Top Tips for a Successful Technical Presentation, but this post is about the actual preparation process and some tips and techniques that might help.
I thought I did a good job, with 72 slides and 8 demos in 75 minutes and only one person said it felt rushed in the comments. ;) Of course, I had about 9 hours of content, but I did prepare in specific ways in order to pull it off.
Know Where Things Are - Beforehand
You can easily waste 2 to 5 minutes over an hour long talk looking for crap. Seriously, I don't need to see how slow you are with Explorer. If you want to have your audience rush the stage, be slow in finding stuff. ;)
Make a folder of links that is specific to your talk. I made one and numbered each link in the order I was going to use them. That includes links to folders, files, browsers, batch files, reset scripts, whatever.
My talk also included a lot of websites that I knew I'd be visiting. I made a Links toolbar in IE and setup links to everything I'd visit, in order.
![]()
My tiny head is on those links not because of my huge ego, but because those links are inside my domain and IE used my favicon.ico. ;)
"Sync to Paper" and Know Your Timing
I'm a gadget guy, sure, and I've got the same todo.txt file on my desktop that the rest of you do, but there's really something about "syncing to paper." before every talk I write a few things down. I do it on a Moleskine notebook that I wrote about in my Personal Systems of Organization post.
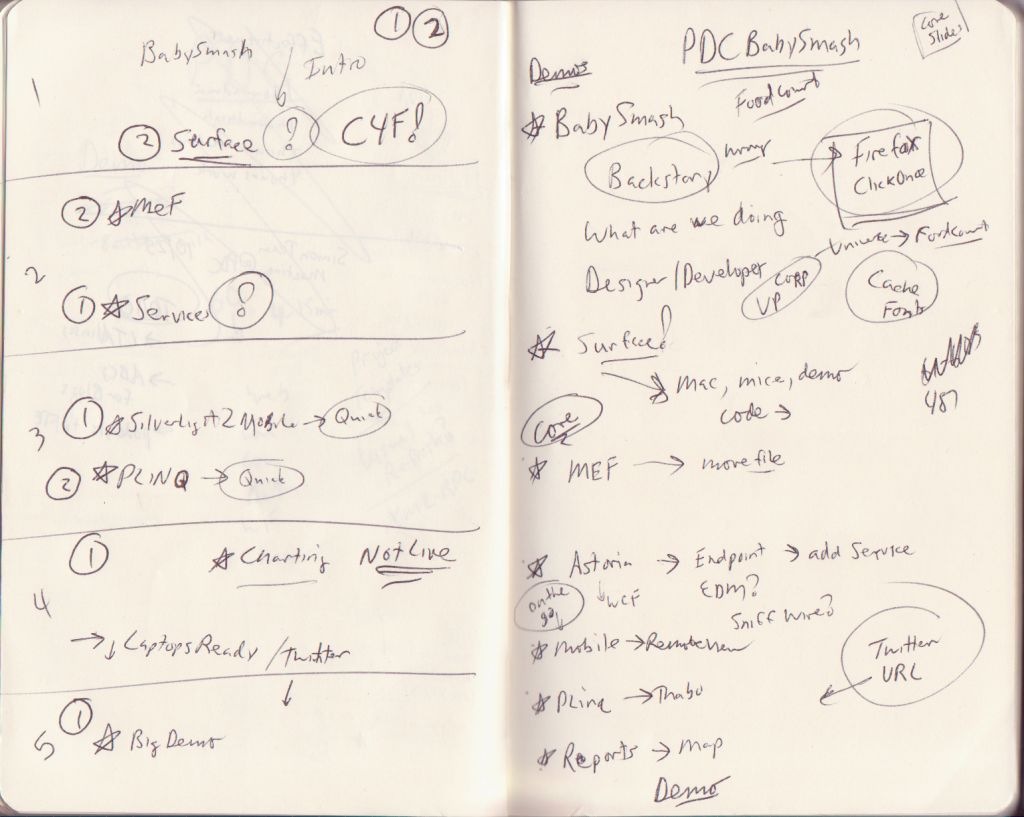
Over the years I've come up with a few techniques on paper that have helped me greatly. Scanned below is the notes I used in my PDC talk.
On the left-hand side you'll see 5 sections, numbered from top to bottom. I make one section per 15 minute segment. This was a 75 minute talk, so there's 5 sections. Sometimes I'll take the FIRST and LAST section and split them into 5/10 and 10/5 respectively. Regardless of how you do it, the point here is to know these things:
- Know Where You Are Supposed to Be
- I use the segments to let me know where I'm supposed to be at 15 min, 30 min, etc. Looking at the notes, if I'm on the PLINQ demo and it's only 20 minutes in, I'm going WAY too fast for example.
- Know Where You Are Going
- It's nice to be free of knowing what's next. The mind can free associate better if it isn't saddled with where it's headed. That's the paper's job. I glance down just to see that I'm on track.
- Know Your Pacing and Know What You Can Drop
- On the left side I've numbered the demos 1 or 2. The #2's I can drop if I need to save time. The #1's can't be dropped or it'll ruin everything. Have enough demos to fill the time, but also know ahead of time which demos to drop if need be.
Know Your Narrative and Where to "Pivot"
If you've ever been unfortunate enough to come upon me freaking out before a talk at a conference, I've likely accosted you and run through the narrative or the "story arc." I keep doing this until it really resonates with me and the half-dozen folks I abuse regularly, like Phil Haack and Rob Conery.
It's all the same basic middle-school speech stuff we've all learned before, but I'm constantly reminding myself of these questions:
- Why is the audience there?
- Who is the audience?
- How can I avoid wasting their time?
- What's the one thing they should get out of the talk?
I also try to focus on a story arc that looks like:
- What is this?
- This is it.
- What was that?
 Seems silly, but it works. You'll see that I repeat myself four or five times to make sure important points get hit and pounded in. This style of arc works in most technical talks, but others are more complex so I use what I call a "pivot point."
Seems silly, but it works. You'll see that I repeat myself four or five times to make sure important points get hit and pounded in. This style of arc works in most technical talks, but others are more complex so I use what I call a "pivot point."
I call it that because in basketball once you've planted your feet you have to pivot on one foot. You can move all over as long as you keep that one foot planted. If the basketball analogy doesn't work for you, then think of holding your finger on a chess piece while you think of your next move.
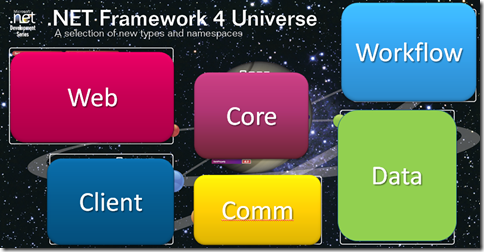
For the PDC talk, we had these nice posters to pass out. They look nice as placemats or on the wall, but they look busy on a slide, so I covered them with bright colored shapes. The Core shape was my pivot point. I'd start there, go to Client, then come back to Core. I'd go to Data, then back to Core. Just like that, Rinse, Repeat.
If you've got a meandering talk, like I did, finding a place to keep coming back to can really help. It helps me.
Have a Pre-Talk Checklist and Demo Reset
Make a complete list of everything that you need to do before your talk. If that means find a Diet Coke and use the bathroom, fine, put it on the list. Here's mine for this talk, unedited.
reset the database
resize and prep the browser
cache the font list
remove my son's face from the xaml
* Pick up the Samsung SilverLight Phone
Test the Phone remote viewing software
prep the mac, test the mac's video output (1280)
*dvi-vga adapter for the mac
check all font sizes in all apps
run zoomin
shutdown services, and the mesh
Warn orcsweb that traffic is coming
I had a bunch of stuff that could have gone wrong if I hadn't checked ahead of time. The Mac I used for the Surface demo only output at 1280x1024. I checked that with the tech guy at 8am. I didn't have a DVI-VGA adapter, so I got one at Radio Shack. I went into every app I was going to run and made sure the fonts were at a visible size (I like Consolas 15pt). I also shutdown all non-essential services. ALL of them. I go from 107 programs running to less than 50. I shutdown piles of stuff in Services.msc like "Infrared Service" and all that crap. I called my ISP, Orcsweb, and warned them I was doing a demo so they'd babysit the box and not think there was an attack.
Preparations like this, and batch files that reset your demos, drop and recreate your database, clear caches, prime caches or whatever administrivia you need, just take a few minutes to do, but they make a presentation look much more professional.
Related Posts
About Scott
Scott Hanselman is a former professor, former Chief Architect in finance, now speaker, consultant, father, diabetic, and Microsoft employee. He is a failed stand-up comic, a cornrower, and a book author.
About Newsletter